
Uber et Airbnb ont récemment communiqué sur la mise à disposition volontaire de données issues de leurs services respectifs. Que valent vraiment ces données ? Permettent-elles de répondre aux questions que ces plateformes posent aux territoires ? Ce qui se joue ici c’est bien la capacité à disposer des données pour réguler les grandes plateformes du numérique.
Uber Movement est accessible depuis l’été 2017 pour les villes de Boston, Washington, Manille et Sydney. Les données concernant la région parisienne sont disponibles depuis fin octobre. « Rendre service aux villes et contribuer à répondre à leurs défis de transport et d’aménagements urbains” sont les deux objectifs annoncés officiellement lors du lancement de la plateforme. Concrètement, pour se connecter à Uber Movement il faudra tout d’abord vous inscrire sur la plateforme avec votre email. Les données disponibles concernent les temps de transport entre deux points (aggrégés à des zones IRIS de l’INSEE). Vous pourrez aussi sélectionner, via l’interface des périodes précises (par exemple une seule semaine en 2016 ou 2017, ou le pic de trafic du matin) et télécharger l’ensemble dans un fichier au format CSV. Les données sont disponibles en licence CC-BY-NC, c’est à dire que leur usage commercial n’est pas autorisé.

Dataville by Airbnb
L’annonce du programme Dataville par Airbnb a coincidé avec le salon des Maires de France qui s’est tenu il y a quelques semaines à Paris. A vrai dire il ne s’agit pas d’une coincidence, car dans sa communication officielle Airbnb vise clairement les élus des territoires, expliquant que « le portail permettra aux municipalités de mieux suivre le développement de l’activité touristique via Airbnb sur leur commune, son impact positif sur l’attractivité de leur commune comme sur le pouvoir d’achat de leurs administrés ». L’entreprise insiste d’ailleurs sur son effort de transparence.
Que trouve-t-on sur la plateforme Dataville ?
- Le nombre d’annonces dans la ville au 1er septembre 2017
- Le nombre de voyageurs accueillis entre septembre 2016 et septembre 2017
- Le nombre de pays dont sont originaires les voyageurs qui y ont séjourné
- Le revenu annuel médian d’un hôte dans la commune
Toutes ces données sont visualisables via une interface web (comme chez Uber Movement) mais pas du tout téléchargeables (contrairement à Uber).

Open Data où es-tu ?
Commençons très vite par régler ce point: difficile de parler de données ouvertes dans l’exemple d’Airbnb ou d’Uber. Les données d’Uber, bien que téléchargeables, sont diffusées avec une licence qui ne permet pas de les qualifier d’open data car elle interdit expressément tout usage commercial. De même, le fait que l’inscription soit requise pour accéder aux données d’Uber Movement constitue un frein à la réutilisation. C’est pas de l’open data, point.
Des données bien inoffensives
Mais là n’est peut-être pas l’essentiel. Que peut-on dire des données qui sont ainsi volontairement exposées par ces deux entreprises ? Tout d’abord qu’il s’agit bien de données originales, au sens de « qui n’ont pas été exposées auparavant« .
Impossible, avant Uber Movement, de connaître l’historique des temps de transport avec ce niveau de détail. Et Airbnb propose bien, avec Dataville, des données qui n’étaient pas auparavant facilement accessibles, par exemple le nombre de voyageurs ou le nombre de pays d’origine.
Ces données volontairement mises à disposition ont un autre point commun: elles sont inoffensives ! Elles permettent difficilement de répondre aux questions que posent ces plateformes sur les territoires.
Prenons quelques exemples pour nous en convaincre.
Si je suis élu d’une ville où Uber propose son service de VTC, je peux par exemple m’interroger sur son impact sur la congestion urbaine. Est-ce que les clients d’Uber auraient par exemple pu utiliser le réseau de transport en commun, ou est-ce que le VTC permet de pallier une offre défaillante ? Rien dans les données d’Uber Movement ne vous permettra de répondre à cette question. Vous aurez les temps de parcours (ce qui n’est pas inintéressant) mais rien sur le nombre moyen d’utilisateurs du service sur ce même parcours (ce qui serait beaucoup plus utile !), en respectant bien sûr les seuils du secret statistique.
Second exemple, avec Airbnb. Quels sont les termes du débat public concernant Airbnb ? J’en recense au moins trois. Le premier est le risque d’éviction dans les quartiers les plus touristiques, les propriétaires préférant mettre leur logement sur Airbnb que de le louer à l’année (il suffit d’être une fois passé dans le Marais vers 9h-10h quand tout le monde quitte son logement avec des grosses valises pour se rendre compte de quoi l’on parle !).
Second débat, la présence, sur la plateforme, de propriétaires professionnels, bien loin de l’image cool et sympa de celui qui accueille des touristes sur le canapé du salon. Plusieurs articles de presse se sont ainsi fait l’écho de propriétaires qui possèdent plusieurs appartements (voire dizaine d’appartements) sur la plateforme…
Troisième débat, les revenus générés par la plateforme pour les « hôtes » selon la terminologie d’Airbnb. S’agit-il de revenus accessoires ou bien de revenus dignes d’une activité principale (et donc professionnelle) – et qui intéressent donc l’administration fiscale ?
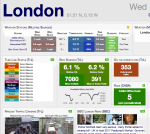
Là encore difficile de répondre à ces questions avec les données mises à disposition par Airbnb. Le niveau de granularité des données est à la commune, pas à l’arrondissement et encore moins au quartier ou à la zone Iris. Pour Paris, on apprend par exemple que 65 000 annonces sont disponibles sur une année, que 2 millions de voyageurs de 178 nationalités différentes ont fréquenté un appartement Airbnb dans la capitale.
C’est grand, Paris. Ce n’est sûrement pas avec ce genre de données qu’on va pouvoir comprendre un peu finement la réalité de l’impact d’Airbnb dans chaque quartier de la capitale !
J’ai fait la même recherche pour la ville de Rennes, et il est précisé que le revenu annuel d’un hôte est de 1400 euros, soit un peu plus de 100 euros par mois. A première vue cela correspond donc bien à des revenus accessoires, du « beurre dans les épinards » (oui, en Bretagne on aime autant le beurre que les épinards…).
Il faut donc aller lire la définition de la métrique selon Airbnb: « valeur médiane du revenu total gagné par l’hôte sur la période d’un an couverte par l’étude. Le revenu annuel est présenté pour un hôte type« . Qu’est-ce qu’un « hôte type » ? L’histoire et Airbnb ne le racontent pas, donc nous sommes en droit d’imaginer. Peut-être qu’un hôte type c’est par exemple un propriétaire qui n’a qu’un appartement et qui ne le met en location que quelques jours par mois ? Autant dire qu’avec de telles métriques nous ne sommes pas prêt de pouvoir répondre à la question de la professionnalisation des « hôtes » Airbnb !
D’ailleurs quand on veut en savoir plus sur le programme on est renvoyés vers le site Airbnb Citizen qui vous propose, au milieu de nombreux témoignages d’utilisateurs de la plateforme, de relayer les campagnes d’influence à destination des élus, comme celle ci-dessous.

C’est plus subtil que du Data-washing
Spontanément nous pourrions crier au data-washing, c’est-à-dire une tentative de se refaire une virginité en publiant des données inoffensives.
Il me semble que les initiatives dont nous parlons ici sont un peu plus subtiles. Ce qui est très clair ce que le choix des données mises à disposition ne doit rien au hasard. Ce n’est pas à un datascientist de chez Uber ou d’Airbnb qu’on va apprendre que des données agrégées sont beaucoup moins utiles que des données détaillées ! Ces sociétés sont réputées pour leur maîtrise des données, on ne peut pas penser une minute qu’elles proposent ces données-là sans avoir envisagé ce qui pourrait (ou plutôt ne pourrait pas) en être fait.
Je pense plutôt que ces initiatives illustrent parfaitement la notion de donnée comme actif stratégique telle que nous la définissions avec Louis-David Benyayer dans Datanomics.
Pour Airbnb ou Uber, la donnée est devenue l’objet et le support de la relation avec les territoires. Lever, ne serait-ce que très légèrement, le voile sur les données c’est aussi se mettre en ordre de bataille pour les discussions à venir, notamment sur les possibles régulations de ces plateformes.
C’est aussi montrer pour mieux cacher, au moment même où les principales métropoles semblent de plus en plus préoccupées par l’impact de ces plateformes sur leur territoire. Si l’on voulait vraiment rentrer dans une régulation par la donnée, telle que proposée par Nick Grossman, alors on ne pourrait pas se contenter des données que les plateformes voudront bien mettre à disposition. La Commission européenne s’intéresse d’ailleurs beaucoup aux données d’intérêt général (1): c’est un outil essentiel pour lutter contre l’asymétrie d’information qui caractérise la relation entre plateformes et territoires !
(1) dans le cadre de la révision en cours de la directive sur les informations du secteur public (PSI).













")
")

