Google vient de lancer en mode bêta Google Dataset Research un moteur de recherche dédié à la découverte des jeux de données ouvertes. L’annonce a été diversement accueillie au sein de la communauté de l’open data, certains y voyant une confirmation que l’open data est devenu un vrai sujet grand public, d’autres s’inquiétant du rôle que pourrait jouer à terme Google comme point d’accès unique à l’offre de données ouvertes.
Je vous propose dans ce billet de découvrir les fonctionnalités de ce nouveau outil, d’en expliquer rapidement le fonctionnement et in fine d’en montrer les limites. Car il n’y a pas de miracle: la découvrabilité des données est un problème complexe que Google, malgré sa bonne volonté et son expertise n’a pas (encore) réussi à résoudre.
Qu’est-ce Google Dataset Search ?
Google Dataset Search est accessible en ligne via un sous-domaine de Google.com. Le moteur de recherche fonctionne à la manière de Google Scholar: il référence des jeux de données indépendamment du portail sur lequel ils sont hébergés.
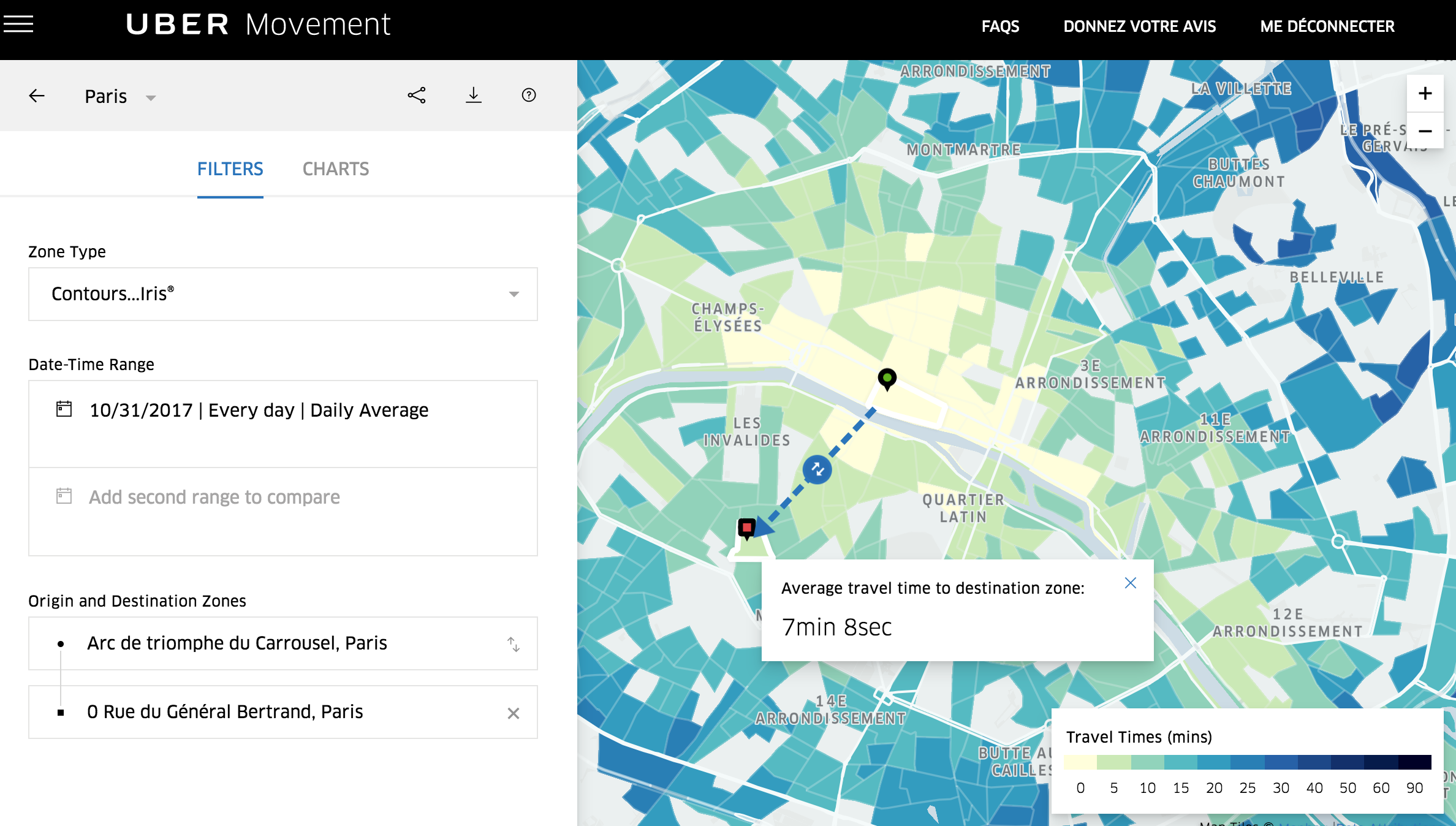
De prime abord, l’utilisateur du moteur de recherche « classique » Google ne sera pas dépaysé: la page d’accueil propose un unique champ de recherche, comme sur le moteur Google.fr. Quand on commence à saisir une expression de recherche, un système d’auto-complétion vous propose plusieurs résultats.

L’auto-complétion montre rapidement ses limites dans cette version bêta. Ainsi si l’on commence à taper l’expression « réser … » (par exemple pour trouver la réserve parlementaire) Google Dataset Search nous renvoie une liste de résultats très hétéroclites, bien moins que cohérente que les suggestions de l’auto-complétion pour la même expression du moteur Google (ci-dessous): « réserve parlementaire, réservez votre ferry au meilleur prix (sic: le site est lancé depuis 1 semaine, mais les apprentis sorciers du SEO s’en emparent déjà!), information cadastrale pour la réserve indienne du village des Hurons Wendake, réserve de salmonidés de l’Estuaire de l’Orne, … »
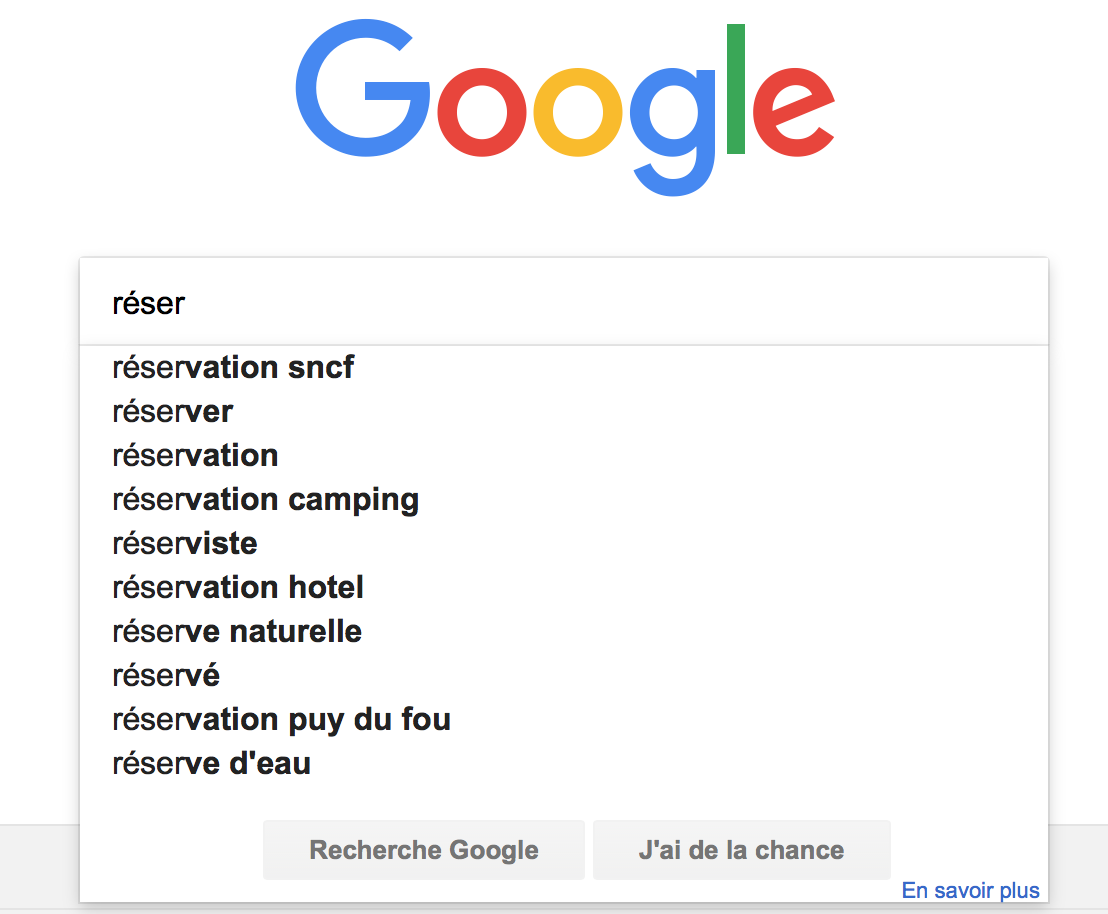
On peut imaginer que cette fonctionnalité va s’améliorer avec le temps, cette première version ne disposant pas, pour l’instant, de retours utilisateurs pour déterminer les jeux de données les plus pertinents pour une requête.
Le nombre de citations, une idée séduisante (dans l’absolu)
L’impression de familiarité qui se dégageait de la page d’accueil disparaît totalement dès la présentation des résultats. La liste figure à gauche (sous la forme d’onglets) et la page présente les méta-données du jeu de données ainsi que le logo du producteur, quand il est disponible.

Comme cela a déjà été souligné par d’autres, notamment ce billet de Singapour, l’expérience utilisateur n’est pas à la hauteur de la qualité à laquelle Google nous avait habitué, même en mode bêta. Ici le moteur ne propose ni recherche par facette, ni tri selon la date de fraîcheur ou format de fichier par exemple. C’est minimaliste.
Chaque résultat mentionne le titre du jeu de données, le ou les site(s) sur lesquels on peut le télécharger ainsi qu’un ensemble de métadonnées: la date de création, de dernière mise à jour, le nom du producteur, la licence et les formats disponibles.
Plus intriguante est la fonction qui liste le nombre de citations du jeu de données dans Google Scholar (le portail de Google qui recense les articles scientifiques publiés en ligne). L’idée est très séduisante: compter le nombre d’articles scientifiques qui utilisent un jeu de données pourrait amener une autre manière de mesurer l’impact de l’open data. Hélas, trois fois hélas, là encore l’expérience proposée par Google Dataset Search est décevante. Sur les 158 articles qui sont censés citer les données de la réserve parlementaire, une très grande majorité ne font en réalité qu’évoquer l’existence de cette réserve parlementaire. Bien peu d’entre eux citent le jeu de données lui-même ou les données qu’il contient.
J’ai fait le même test sur les « prévisions Météo-France« , un jeu de données disponible sur data.gouv.fr et indexé par Google Dataset Search. Parmi les résultats liés dans Google Scholar on retrouve même un vieil article scientifique avec la phrase suivante: « faute d’accès aux prévisions Météo-France, nous avons eu recours à une autre source de données« . Ce qui compte comme une citation est donc en fait un non-usage (sic).
Il y a donc encore du travail pour faire de cette métrique une mesure objective et fiable de l’utilisation des données ouvertes par la recherche.
Le problème de la découvrabilité
Le jugement peut paraître sévère mais, dans cette première version bêta, Google Dataset Search ne fait pas vraiment le job. Il répond de manière incomplète à l’enjeu principal, celui de la découvrabilité des jeux de données.
La découvrabilité est aujourd’hui l’une des grandes difficultés à laquelle nous sommes confrontés tant en France qu’à l’étranger. L’offre de données est plus importante que jamais, mais elle n’est pour autant pas facile à trouver.
Pourquoi ? On peut avancer plusieurs explications:
- la multiplicité des portails et des sources de données: rien qu’au niveau français l’observatoire de l’open data des territoires a recensé plus d’une centaine de plateformes, portails ou sites web qui hébergent des données ouvertes, cela joue d’ailleurs clairement en faveur de Google Dataset Search qui offre un point d’accès unique,
- l’extrême diversité des thématiques couvertes par les jeux de données et l’absence de standardisation pour une très grande majorité des jeux de données,
- des niveaux de complétude des méta-données très variables d’un producteur à l’autre. Un jeu de données qui traite de la même thématique peut porter des titres très différents selon deux régions… alors on imagine ce que cela donne entre deux pays !
- la difficulté à analyser le contenu lui-même des jeux de données, c’est à dire à ne pas se limiter aux méta-données.
Dans cet article de janvier 2017, publié sur le blog Google AI (tiens, tiens) et consacré justement au problème de la découvrabilité des jeux de données on peut y lire la phrase suivante: « there is no reason why searching for datasets shouldn’t be as easy as searching for recipes, or jobs, or movies« . Heu… Comment dire… ? Des raisons on en voit au contraire beaucoup, j’ai commencé ci-dessus à en citer quelques unes. Mais l’approche par les méta-données, telle que Google l’a retenu est un sacré pari.
Ce pari, c’est celui de s’en remettre aux producteurs de données pour qu’ils fournissent des méta-données les plus complètes et les plus pertinentes possibles. L’expérience montre que le travail de sensibilisation des producteurs sur ce point reste encore largement devant nous. Et c’est là que Google Dataset Search peut y contribuer.
Avec Google Dataset Search, le géant américain pourrait reproduire ce qu’il a déjà réussi dans le domaine de l’information transport: encourager les producteurs à adopter un standard (de données ou de méta-données) en leur faisant miroiter une visibilité accrue via leur présence dans les produits Google.
l
De la même manière que, pour apparaître dans Google Transit il faut publier ses données au format GTFS, pour apparaître dans Google Dataset Search il faut adopter le modèle de méta-données défini par schema.org, organisation à but non lucratif dont le premier sponsor est… Google.
L’alternative à cette approche par les méta-données consisterait à regarder le contenu lui-même des jeux de données pour être par exemple capable de reconnaître un identifiant comme un numéro SIRET. Or, comme le confirme cet article de Nature pour le moment Google n’a pas prévu de regarder le contenu des jeux de données eux-mêmes.
Comment faisait-on avant Google ?
Tous les éditeurs de plateforme de données ouvertes ont tenté, avec un succès plus ou moins relatif, de répondre à cet enjeu de découvrabilité. La recherche par facette, que l’on retrouve sur quasiment tous les portails, est un moyen de rendre les données plus faciles à identifier. Ainsi on peut raffiner progressivement les résultats d’une recherche en affinant sur le producteur, la date de mise à jour, la couverture géographique et bien d’autres critères. Data.gouv.fr, les plateformes OpenDataSoft ou encore Enigma et Socrata de l’autre côté de l’Atlantique procèdent ainsi. Certains proposent aussi des approches thématique, des tags, des catégories, etc. D’autres pistes consistent à identifier des liens entre les jeux de données, par exemple ceux qui partagent un identifiant commun.

Je ne dis pas que les solutions existantes sont parfaites. C’est encore très loin d’être le cas. Quand le catalogue de données est important il est parfois malaisé de savoir si une recherche infructueuse signifie que le jeu de données n’existe pas… ou qu’on n’a pas su le trouver !
Quelles implications pour l’open data ?
A ce stade les producteurs de données et les responsables de plateformes open data n’ont rien à perdre à rendre leur offre découvrable par Google. Tout ce qui peut rendre un jeu de données plus facile à découvrir est bon à prendre.
L’impact en terme d’audience reste à confirmer, mais pour le moment il est faible. Pour data.gouv.fr par exemple, Google Dataset Search a amené la semaine dernière un peu plus de 550 visites … sur un total de 81 000. Bien sûr on peut imaginer que cet apport d’audience pourrait être beaucoup plus important si cette nouvelle fonctionnalité de recherche de données est à terme intégrée dans le moteur Google lui-même – au même titre que la recherche dans les images ou les actualités, qui étaient autrefois autant de produits Google distincts avant d’être intégrés dans le moteur principal.
Il sera alors temps de se poser la question du risque de désintermédiation des plateformes open data au profit du moteur de recherche, risque que nous avions déjà évoqué il y a quelques années pour les sites de cinéma…
Et vous, qu’en pensez-vous ? Faut-il se réjouir de cette nouvelle initiative ou s’en inquiéter ?