
« Open Data Commons » (by jwyg)
A l’occasion de la Semaine européenne de l’Open Data à Marseille, je suis invité à intervenir sur le sujet des indicateurs des politiques publiques d’ouverture des données. Comment mesurer et évaluer les programmes Open Data ? Est-ce vraiment si difficile à faire ? Ce billet de blog vous propose un résumé de mon intervention.
1 – Des indicateurs pour chaque étape des projets
Le chercheur britannique Tim Davies recense sur son carnet de recherche en ligne plusieurs types d’outils d’évaluation et en propose une première classification. Il les distingue selon l’objectif poursuivi :
– mesurer un « état de préparation » (readiness assessment tool) : la boîte à outils développée par la Banque Mondiale comprend ainsi une check-list très complète des facteurs susceptibles de favoriser une politique durable d’ouverture des données,
– mesurer l’implémentation des politiques, leur mise en oeuvre: le plus connu (et sans aucun doute l’un des plus anciens) est le modèle des 5-étoiles défini par Tim Berners-Lee et le W3C (la classification met l’accent sur les critères techniques de mise à disposition des données, le 5ème étoile étant réservées aux approches de type web sémantique),
– enfin, mesurer l’impact des politiques open data, qu’ils soient directs (création de services ou d’applications à partir des données ouvertes) ou indirects (développement économique, renforcement de la transparence, contribution à l’atteinte des objectifs de politique publique,…).
Tim Davies souligne le fait que la plupart des outils disponibles se concentrent sur les deux premières étapes (l’état de préparation et l’implémentation) mais que l’on ne dispose pas à ce jour d’un modèle d’évaluation complet pour mesurer les impacts de l’open data. Je partage totalement cette analyse – et j’aurai l’occasion dans ce billet de proposer quelques pistes en ce sens.
Il y a exactement 2 ans, j’étais déjà invité à Marseille (qui refuserait une invitation dans la cité phocéenne au mois de juin ?) à l’occasion de l’Open Data Garage (ma présentation « évaluer l’impact économique de l’open data local » est toujours en ligne). Il y a deux ans, la plupart des outils et des modèles cités par Tim Davies n’existaient pas encore, il me semble donc que nous allons dans le bon sens… Pour vous en convaincre, je vous propose dans un premier temps de détailler quelques outils dont nous disposons aujourd’hui.
2 – Présentation de trois outils pour évaluer les politiques open data
La Banque Mondiale a développé un outil de mesure de l’état de préparation (readiness assessment tool, traduit en français) qu’elle utilise dans le cadre de ses missions d’audit et de conseil au niveau international – et plus particulièrement dans les pays émergents. A noter que ce document fait partie d’une très intéressante boîte à outils sur le sujet (lecture recommandée).
Cet outil se concentre sur les conditions favorables à une politique d’ouverture des données. Pour chaque élément évalué (leadership, cadre réglementaire, structure institutionnelle, données au sein du gouvernement, engagement citoyen, écosystème, financement), des exemples précis de questions sont formulés, ainsi que des éléments de preuve. A l’origine développé pour évaluer des pays, l’outil pourrait tout à fait s’adapter pour des évaluations au niveau local. L’attention portée notamment sur la gouvernance (et l’importance d’un appui politique explicite à la démarche) me semble valable quel que soit l’échelon étudié.
L’outil MELODA (methodology for releasing open data) est proposé par Alberto Abella, l’un des cofondateurs du chapitre espagnol de l’Open Knowledge Foundation. Meloda s’intéresse à la phase d’implémentation et mesure en particulier le degré d’ouverture des données.
L’outil mesure les sources de données (locales, nationales ou internationales) selon des critères juridiques, techniques et d’accessibilité de l’information. C’est l’un des outils les plus proches de la définition que je retiens d’une donnée ouverte. Chacun des 3 critères est évalué sur une échelle à 5 niveaux (par exemple pour le critère juridique, la plus forte note est attribuée aux sources de données n’imposant qu’une obligation d’attribution – une licence de type Licence Ouverte d’Etalab par exemple). L’auteur complète ainsi utilement les 5-étoiles de Berners-Lee. Je dis utilement parce qu’une donnée qui serait en tous points conformes aux objectifs du web sémantique mais proposée avec une licence non-ouverte n’aurait pas grand sens d’un point de vue pratique !
L’initiative Open Data Census de l’Open Knowledge Foundation vise à comparer les niveaux d’engagement dans l’open data de plusieurs pays. L’OKFN a ainsi défini une liste de 10 jeux de données. On y retrouve par exemple les résultats des élections, les budgets des Etats, le registre des entreprises, les codes postaux géolocalisés ou encore les horaires des transports publics. Chaque jeu de données est évalué, par pays, sur une échelle à 7 niveaux (disponibilité, ouverture, …).
Rien n’empêche d’adopter une approche semblable pour des initiatives locales d’open data. Nous pourrions ainsi définir une liste de 10 jeux de données qui nous semblent pertinents (selon quels critères ?) et évaluer leur disponibilité et ouverture sur les portails open data des collectivités français…
Il convient bien sûr de rajouter à cette courte liste (je vous renvoie vers le blog de Tim Davies pour un recensement plus exhaustif) quelques initiatives françaises : le référentiel OpQuast recense les bonnes pratiques en matière de portail open data. Il peut tout aussi bien servir à agir (préparer un portail) qu’à évaluer. Ce double usage (action / évaluation) est intéressant, mais on gardera toujours à l’esprit qu’un indicateur qui est aussi un objectif n’est plus un indicateur ! Enfin, on m’a signalé le projet Odalisk qui vise aussi à comparer les initiatives (le site principal ne fonctionne pas à l’heure où j’écris ces lignes, mais le code source est disponible sur GitHub – ce qui n’est pas si mauvais signe).
3 – Les 3 phases de l’ouverture des données : semer, faire pousser, récolter
Dans la panoplie d’outils dont nous commencons à disposer en France et à l’international, force est de constater que la mesure des impacts (économiques, sociaux, sociétaux, démocratiques, …) de l’open data n’est pas le champ le mieux documenté. Notons toutefois que plusieurs programmes sont en cours, notamment à l’UK ODI (et je vous renvoie en priorité à l’interview de Tim Berners-Lee qui déplore « nous n’avons pas d’économistes de la donnée« ), pour explorer en particulier la question de la valeur des données.
Pourquoi ne dispose-t-on pas aujourd’hui de la même richesse méthodologique que pour les autres phases de l’open data ? J’y vois plusieurs raisons, la première étant la perspective historique. Les outils d’évaluation de l’état de préparation ou d’implémentation sont aussi le fruit du retour d’expérience des premières initiatives d’open data qui ont en quelque sorte permet de définir des « bonnes pratiques » à partir du terrain.
La question de la mesure de l’impact, et en particulier de ses effets dans le temps, est une question qui se pose pour les initiatives qui ont déjà un peu de « bouteille » – et en France on ne parle là que d’une demi-douzaine d’initiatives ! Au-delà de ce côté « pionniers », le temps joue aussi à mon avis dans notre capacité à bien comprendre les impacts, et en particulier les impacts de second ou de troisième niveaux, des politiques d’ouverture des données publiques.
On a aujourd’hui un cadre théorique qui explique bien cet effet-retard de la mise à disposition des données, je pense notamment au rapport de Marc de Vries et Geoff Sawyer pour l’Agence spatiale européenne. Les deux auteurs distinguent ainsi 3 phases dans les effets de l’ouverture des données : une phase d’ensemencement (sowing phase), une phase de culture (growing phase) et une phase de récolte (harvesting phase).
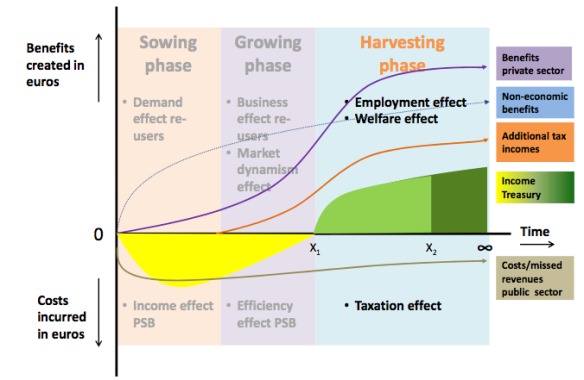
Les 3 phases de l’ouverture des données – source : Marc de Vries et Geoff Sawyer pour l’European Space Agency
4 – Don’t ask, please tell !
Hormis le temps, la difficulté est d’identifier l’ensemble des réutilisations qui peuvent être réalisées à partir des données ouvertes. L’open data ne sert pas qu’à réaliser des applications mobiles, la donnée ouverte est aussi une matière première pour nombre d’organisations et d’entreprises.
Le principe du « don’t ask, don’t tell » est à mes yeux un élément essentiel de l’approche d’ouverture des données. On ne contrôle pas a priori les usages – sauf dans le cas de certaines licences proposées par le Grand Lyon qui imposent une déclaration préalable d’usage (j’y reviendrais dans un prochain billet).
Il faudrait donc passer au principe du don’t ask, please tell ! C’est-à-dire encourager les réutilisateurs à partager leurs expériences de réutilisation, à raconter les gains (économiques et sociaux) qu’ils tirent de la réutilisation des données ouvertes. Il faudrait expérimenter un principe de « trackback » pour les données, à l’instar de ce que l’on trouve sur les blogs.
5 – Des premières pistes pour avancer
Il n’est certes pas aisé de mesurer les impacts de l’open data pour les multiples raisons que je viens d’évoquer. Mais ce n’est pas une raison pour ne pas essayer à partir des éléments dont nous disposons déjà.
Je vois deux premières pistes que nous pourrions explorer : le suivi longitudinal des réutilisations de 1er niveau (ie. par exemple les applications ou services développés dans le cadre de concours) et la mesure des effets de type « boucle de rétroaction« .
Concernant les réutilisations de premier niveau, c’est-à-dire les applications ou services qui ont été réalisés à partir des données ouvertes, une bonne partie d’entre eux sont identifiables : soit ils ont participé aux actions d’animation (concours, hackathons, …), soit ils publient leurs services (une veille sur les boutiques d’applications mobiles, par exemple, s’impose).
L’intérêt ici n’est pas tant de mesurer le nombre de services crées, mais plutôt d’évaluer des dynamiques d’usage dans le temps: combien d’utilisateurs actifs sur une période de référence (une semaine, un mois) ?
Les programmes de labellisation sont aussi une occasion rêvée de demander aux développeurs de partager leurs chiffres d’utilisation (et la plupart l’accepteront volontiers en échange d’une meilleure visibilité pour leur réalisation). On compare ensuite ces données obtenues à des moyennes pour le même type de service rendu – ce ne sont pas les services d’analytics qui manquent en ligne, tant pour le web que pour le mobile…
Le second type d’évaluation que nous pourrions mettre en place est liée à l‘effet des boucles de rétroaction. On va pouvoir ainsi introduire un lien direct avec les objectifs de politique publique poursuivis par la collectivité. Ainsi, si l’on veut promouvoir l’usage des transports en commun ou des modes doux dans une ville, on peut chercher à identifier l’effet des différentes applications disponibles sur le report modal.
Objectif ambitieux me direz-vous, mais pourtant réalisable dès aujourd’hui: ainsi quand on réalise une enquête sur l’utilisation des vélos en libre-service (Vélib), pourquoi ne pas chercher à identifier la part des utilisateurs qui connaissent les applications, qui les ont déjà utilisées, et leur importance dans la décision de recourir à ce mode de déplacement… ? L’information peut aussi contribuer à changer un comportement, encore faut-il se donner les moyens de le mesurer !

 « Open Models, le livre » est le fruit des rencontres Open Experience initiées de janvier à juin 2014 par Without Model. L’idée: faire le tour des modèles économiques de l’open en 6 étapes, de l’art au manufacturing en passant par la data, la science, l’éducation et le logiciel. Retour sur ma modeste contribution à ce projet.
« Open Models, le livre » est le fruit des rencontres Open Experience initiées de janvier à juin 2014 par Without Model. L’idée: faire le tour des modèles économiques de l’open en 6 étapes, de l’art au manufacturing en passant par la data, la science, l’éducation et le logiciel. Retour sur ma modeste contribution à ce projet.

















