Le premier logo de la Commission d’accès aux documents administratifs
La Commission d’accès aux documents administratifs fête ces jours-ci les 40 ans de la loi ayant posé les bases de la transparence administrative dans notre pays. A cette occasion, je vous propose un retour sur les jeunes années de la CADA. A quelques jours de l’application du principe d’open data par défaut et deux ans après la promulgation de la loi pour une République numérique, c’est aussi une manière de regarder dans le rétroviseur: comment passe-t-on d’un principe posé dans la loi à un droit effectif pour les citoyens et adopté par les administrations ?
Pour débuter, une confidence: je suis un grand amateur d’archéologie administrative et plus particulièrement de la lecture d’anciens rapports administratifs. Bref. Je me suis donc plongé avec gourmandise dans les tous premiers rapports d’activité de la CADA que l’on peut retrouver sur le site de la Documentation française.
La place de la technique: du droit d’accès au « droit à la photocopie »
Premier étonnement à la lecture de ces rapports: la place accordée à la question de la technique d’accès: comment accède-t-on concrètement aux documents administratifs ? La technique en vogue, en ce début des années 1980, c’est la photocopie. Il en question 21 fois dans le second rapport d’activité de la CADA qui va d’ailleurs jusqu’à affirmer que « l’absence de cet appareil [photocopieur] vide parfois de sens la liberté d’accès, aussi leur nombre devrait être multiplié, leur prix étudié en fonction du nombre d’exemplaires et leur délivrance obligatoire ».
La possibilité de reproduire des documents administratifs n’est pas seulement un moyen comme un autre d’exercer ce droit d’accès, cela ouvre d’autres usages possibles: photocopier un document (plutôt que le consulter sur place) permet de se constituer un dossier « au cas où ». A contrario, le format des planches cadastrales ne permet pas de les photocopier facilement, diminuant donc de facto la possibilité d’y accéder autrement qu’en allant les consulter sur place !
Cette relation entre le droit et la technique qui permet de l’exercer (la consultation sur place, la photocopie, l’envoi par courrier électronique, etc.) me semble encore tout à fait d’actualité au moment où l’on parle de téléchargements de données ou d’API. Ces techniques ne sont pas neutres, au sens où elles façonnent l’exercice pratique du droit et les usages qui sont alors permis.
D’un droit individuel à un droit collectif
Le second point qui émerge est le double usage du droit d’accès à l’information. Dès ces jeunes années – et je crois que c’est encore le cas aujourd’hui – la vaste majorité des saisines de la CADA concerne des demandes individuelles: accéder à un dossier médical, un dossier employeur, etc. Mais on voit aussi émerger peu à peu des demandes collectives, ou plutôt des demandes qui ne concernent pas uniquement un individu mais bien un collectif. C’est particulièrement visible dans le domaine de l’urbanisme ou de l’aménagement par exemple, où les associations commencent à se saisir de ce nouveau droit dans le cadre de leurs actions.
Là encore il y a je pense matière à réfléchir pour aujourd’hui. Nous avons construit le droit de l’ouverture des données publiques sur la base du droit d’accès. Or majoritairement les données ouvertes concernent des situations collectives et non pas individuelles. En ce sens, la portabilité des données personnelles, renforcée par le RGPD, peut davantage être vu comme l’héritier de ce droit individuel à l’accès…
Un droit qui s’affine et se précise, des actions vers le grand public
Troisième motif récurrent des premières années de la Commission: la construction progressive d’une doctrine autour de la loi d’accès aux documents administratifs. En rendant ses premiers avis, la CADA précise les conditions d’application du droit, au besoin en se référant et en interprétant les intentions du législateur.
L’autre préoccupation majeure des premières années d’existence de la CADA c’est de faire en sorte que ce nouveau droit puisse être connu, et donc exercé, par les citoyens. Le 4 décembre 1981, la CADA organise une journée dédiée à l’accès à l’information sur les ondes de Radio France. Plus de 400 appels seront reçus et orientés durant la journée !
On notera enfin que la question des délais de traitement, et donc celui des moyens alloués à la Commission est évoqué dès le début de son existence… constat (malheureusement) toujours d’actualité.
Google vient de lancer en mode bêta Google Dataset Research un moteur de recherche dédié à la découverte des jeux de données ouvertes. L’annonce a été diversement accueillie au sein de la communauté de l’open data, certains y voyant une confirmation que l’open data est devenu un vrai sujet grand public, d’autres s’inquiétant du rôle que pourrait jouer à terme Google comme point d’accès unique à l’offre de données ouvertes.
Je vous propose dans ce billet de découvrir les fonctionnalités de ce nouveau outil, d’en expliquer rapidement le fonctionnement et in fine d’en montrer les limites. Car il n’y a pas de miracle: la découvrabilité des données est un problème complexe que Google, malgré sa bonne volonté et son expertise n’a pas (encore) réussi à résoudre.
Qu’est-ce Google Dataset Search ?
Google Dataset Search est accessible en ligne via un sous-domaine de Google.com. Le moteur de recherche fonctionne à la manière de Google Scholar: il référence des jeux de données indépendamment du portail sur lequel ils sont hébergés.
De prime abord, l’utilisateur du moteur de recherche « classique » Google ne sera pas dépaysé: la page d’accueil propose un unique champ de recherche, comme sur le moteur Google.fr. Quand on commence à saisir une expression de recherche, un système d’auto-complétion vous propose plusieurs résultats.
L’auto-complétion de Google Dataset Search
L’auto-complétion montre rapidement ses limites dans cette version bêta. Ainsi si l’on commence à taper l’expression « réser … » (par exemple pour trouver la réserve parlementaire) Google Dataset Search nous renvoie une liste de résultats très hétéroclites, bien moins que cohérente que les suggestions de l’auto-complétion pour la même expression du moteur Google (ci-dessous): « réserve parlementaire, réservez votre ferry au meilleur prix (sic: le site est lancé depuis 1 semaine, mais les apprentis sorciers du SEO s’en emparent déjà!), information cadastrale pour la réserve indienne du village des Hurons Wendake, réserve de salmonidés de l’Estuaire de l’Orne, … »
On peut imaginer que cette fonctionnalité va s’améliorer avec le temps, cette première version ne disposant pas, pour l’instant, de retours utilisateurs pour déterminer les jeux de données les plus pertinents pour une requête.
Le nombre de citations, une idée séduisante (dans l’absolu)
L’impression de familiarité qui se dégageait de la page d’accueil disparaît totalement dès la présentation des résultats. La liste figure à gauche (sous la forme d’onglets) et la page présente les méta-données du jeu de données ainsi que le logo du producteur, quand il est disponible.
Résultats pour la requête « réserve parlementaire »
Comme cela a déjà été souligné par d’autres, notamment ce billet de Singapour, l’expérience utilisateur n’est pas à la hauteur de la qualité à laquelle Google nous avait habitué, même en mode bêta. Ici le moteur ne propose ni recherche par facette, ni tri selon la date de fraîcheur ou format de fichier par exemple. C’est minimaliste.
Chaque résultat mentionne le titre du jeu de données, le ou les site(s) sur lesquels on peut le télécharger ainsi qu’un ensemble de métadonnées: la date de création, de dernière mise à jour, le nom du producteur, la licence et les formats disponibles.
Plus intriguante est la fonction qui liste le nombre de citations du jeu de données dans Google Scholar (le portail de Google qui recense les articles scientifiques publiés en ligne). L’idée est très séduisante: compter le nombre d’articles scientifiques qui utilisent un jeu de données pourrait amener une autre manière de mesurer l’impact de l’open data. Hélas, trois fois hélas, là encore l’expérience proposée par Google Dataset Search est décevante. Sur les 158 articles qui sont censés citer les données de la réserve parlementaire, une très grande majorité ne font en réalité qu’évoquer l’existence de cette réserve parlementaire. Bien peu d’entre eux citent le jeu de données lui-même ou les données qu’il contient.
J’ai fait le même test sur les « prévisions Météo-France« , un jeu de données disponible sur data.gouv.fr et indexé par Google Dataset Search. Parmi les résultats liés dans Google Scholar on retrouve même un vieil article scientifique avec la phrase suivante: « faute d’accès aux prévisions Météo-France, nous avons eu recours à une autre source de données« . Ce qui compte comme une citation est donc en fait un non-usage (sic).
Il y a donc encore du travail pour faire de cette métrique une mesure objective et fiable de l’utilisation des données ouvertes par la recherche.
Le problème de la découvrabilité
Le jugement peut paraître sévère mais, dans cette première version bêta, Google Dataset Search ne fait pas vraiment le job. Il répond de manière incomplète à l’enjeu principal, celui de la découvrabilité des jeux de données.
La découvrabilité est aujourd’hui l’une des grandes difficultés à laquelle nous sommes confrontés tant en France qu’à l’étranger. L’offre de données est plus importante que jamais, mais elle n’est pour autant pas facile à trouver.
Pourquoi ? On peut avancer plusieurs explications:
la multiplicité des portails et des sources de données: rien qu’au niveau français l’observatoire de l’open data des territoires a recensé plus d’une centaine de plateformes, portails ou sites web qui hébergent des données ouvertes, cela joue d’ailleurs clairement en faveur de Google Dataset Search qui offre un point d’accès unique,
l’extrême diversité des thématiques couvertes par les jeux de données et l’absence de standardisation pour une très grande majorité des jeux de données,
des niveaux de complétude des méta-données très variables d’un producteur à l’autre. Un jeu de données qui traite de la même thématique peut porter des titres très différents selon deux régions… alors on imagine ce que cela donne entre deux pays !
la difficulté à analyser le contenu lui-même des jeux de données, c’est à dire à ne pas se limiter aux méta-données.
Dans cet article de janvier 2017, publié sur le blog Google AI (tiens, tiens) et consacré justement au problème de la découvrabilité des jeux de données on peut y lire la phrase suivante: « there is no reason why searching for datasets shouldn’t be as easy as searching for recipes, or jobs, or movies« . Heu… Comment dire… ? Des raisons on en voit au contraire beaucoup, j’ai commencé ci-dessus à en citer quelques unes. Mais l’approche par les méta-données, telle que Google l’a retenu est un sacré pari.
Ce pari, c’est celui de s’en remettre aux producteurs de données pour qu’ils fournissent des méta-données les plus complètes et les plus pertinentes possibles. L’expérience montre que le travail de sensibilisation des producteurs sur ce point reste encore largement devant nous. Et c’est là que Google Dataset Search peut y contribuer.
Avec Google Dataset Search, le géant américain pourrait reproduire ce qu’il a déjà réussi dans le domaine de l’information transport: encourager les producteurs à adopter un standard (de données ou de méta-données) en leur faisant miroiter une visibilité accrue via leur présence dans les produits Google.
l
De la même manière que, pour apparaître dans Google Transit il faut publier ses données au format GTFS, pour apparaître dans Google Dataset Search il faut adopter le modèle de méta-données défini par schema.org, organisation à but non lucratif dont le premier sponsor est… Google.
L’alternative à cette approche par les méta-données consisterait à regarder le contenu lui-même des jeux de données pour être par exemple capable de reconnaître un identifiant comme un numéro SIRET. Or, comme le confirme cet article de Nature pour le moment Google n’a pas prévu de regarder le contenu des jeux de données eux-mêmes.
Comment faisait-on avant Google ?
Tous les éditeurs de plateforme de données ouvertes ont tenté, avec un succès plus ou moins relatif, de répondre à cet enjeu de découvrabilité. La recherche par facette, que l’on retrouve sur quasiment tous les portails, est un moyen de rendre les données plus faciles à identifier. Ainsi on peut raffiner progressivement les résultats d’une recherche en affinant sur le producteur, la date de mise à jour, la couverture géographique et bien d’autres critères. Data.gouv.fr, les plateformes OpenDataSoft ou encore Enigma et Socrata de l’autre côté de l’Atlantique procèdent ainsi. Certains proposent aussi des approches thématique, des tags, des catégories, etc. D’autres pistes consistent à identifier des liens entre les jeux de données, par exemple ceux qui partagent un identifiant commun.
Enigma enrichit la recherche avec des classifications, de la taxonomie et de l’éditorialisation (public.enigma.com)
Je ne dis pas que les solutions existantes sont parfaites. C’est encore très loin d’être le cas. Quand le catalogue de données est important il est parfois malaisé de savoir si une recherche infructueuse signifie que le jeu de données n’existe pas… ou qu’on n’a pas su le trouver !
Quelles implications pour l’open data ?
A ce stade les producteurs de données et les responsables de plateformes open data n’ont rien à perdre à rendre leur offre découvrable par Google. Tout ce qui peut rendre un jeu de données plus facile à découvrir est bon à prendre.
L’impact en terme d’audience reste à confirmer, mais pour le moment il est faible. Pour data.gouv.fr par exemple, Google Dataset Search a amené la semaine dernière un peu plus de 550 visites … sur un total de 81 000. Bien sûr on peut imaginer que cet apport d’audience pourrait être beaucoup plus important si cette nouvelle fonctionnalité de recherche de données est à terme intégrée dans le moteur Google lui-même – au même titre que la recherche dans les images ou les actualités, qui étaient autrefois autant de produits Google distincts avant d’être intégrés dans le moteur principal.
Il sera alors temps de se poser la question du risque de désintermédiation des plateformes open data au profit du moteur de recherche, risque que nous avions déjà évoqué il y a quelques années pour les sites de cinéma…
Et vous, qu’en pensez-vous ? Faut-il se réjouir de cette nouvelle initiative ou s’en inquiéter ?
La Commission nationale Informatique et Libertés (CNIL) fête ses 40 ans. La polémique qui a suivi la publication de l’article du Monde « Safari ou la chasse aux Français » est à l’origine de la loi Informatique et Libertés. 40 ans après, j’ai relu l’article qui a mis le feu au poudre. Retour sur le totem (et le tabou ?) de la CNIL.
Safari: système automatisé pour les fichiers administratifs et le répertoire des individus
La première fois que j’ai rendu visite à la Cnil – je crois que c’était en 2012, pour préparer une journée dédiée à l’open data – j’ai attendu mon interlocutrice au pied de l’escalier monumental qui marquait l’entrée des anciens bureaux de la commission.
L’article du Monde titré « Safari ou la chasse aux Français » y figurait en bonne place, comme un totem.
Relire l’article de Philippe Boucher plus de 40 ans après, c’est replonger dans une ambiance d’une autre époque, avec des noms (MM. Marcellin, Poniatowski, Chirac, …) qui évoquent surtout l’ORTF et la Renault 4 .
La France a peur (encore? oui mais cette fois-ci, c’est de l’informatique) – source ina.fr
L’article du Monde débute tout d’abord par une longue présentation, un peu absconse, de l’ordinateur IRIS-80 dont les ministères – et en premier lieu celui de l’Intérieur sont en train de s’équiper. Pour comprendre la fascination-répulsion que ces machines provoquent, il faut se rappeler que, dans les années 1970, on ne compte que quelques centaines de mainframes en France, principalement utilisés pour le secteur bancaire et les administratifs.
Il évoque ensuite le projet Safari, initié dans les années 70 par l’INSEE et dont le déploiement a commencé notamment au Ministère de l’Intérieur. De quoi s’agit-il ?
Dans la note originale de l’INSEE on peut y lire qu’il s’agit avant de tout de faciliter la circulation des informations entre les administrations. Ab initio, le projet SAFARI comporte deux dimensions: la généralisation du répertoire d’identification des personnes physiques et le transfert de ce répertoire sur des bandes magnétiques.
Retrouver un individu prenait alors environ 10 heures, contre quelques minutes après le passage sur des bandes magnétiques.
L’INSEE entrevoit rapidement le potentiel d’un tel système: si tous les Français disposaient d’un identifiant unique et obligatoire on pourrait utiliser ce numéro comme une clé pour interconnecter l’ensemble des fichiers des administrations: fichiers d’état-civil, des impôts, du cadastre, de la santé, etc. La « mise en fiche » de la population est un sujet d’autant plus sensible que la dernière opération de ce genre date de l’Occupation.
Mais ce qui sera surtout pointé du doigt c’est la capacité à interconnecter les bases de données via un numéro personnel unique et obligatoire.
Les risques que cette interconnexion ferait peser sur les libertés, l’article du Monde daté de 1974 n’en parle pas aussi clairement. Il insiste plutôt sur les velléités du ministre de l’intérieur (un certain Jacques Chirac) de mettre la main sur l’ensemble des fichiers administratifs (dont celui des impôts et le cadastre) et sur le manque de réaction du ministère de la Justice. En 1977, Jean-Louis Missika et Jean-Philippe Faivret aka Philippe Lemoine [le trio qu’ils constituaient vec Dominique Wolton formait une sacré bande à l’époque, faudra que je vous raconte ca une autre fois] publient un long article dans la revue Les Temps Modernes où ils pointent ce risque en parlant de « French Interconnexion ».
Un hommage au fonctionnaire inconnu
Ce qui fait la force de l’article du Monde c’est son titre: « Safari ou la chasse aux Français ».
Il faudra un jour ériger un moment au fonctionnaire anonyme qui a baptisé le projet avec un tel acronyme (Safari: système automatisé pour les fichiers administratifs et le répertoire des individus).
C’est bien cet acronyme, accolé à la mention « la chasse aux Français », qui fait mouche. Imaginons un instant que le fichier SAFARI se soit appelé dès sa conception le « répertoire national d’identification des personnes physiques » [son nom officiel], vous voyez le titre du Monde: « RNIPP ou la chasse aux français ? ». Ca fait moins flipper, avouons-le.
A quoi cela tient parfois, les choses ? A trois fois rien. Au choix d’un fonctionnaire anonyme et à une formule bien tournée d’un journaliste.
Imaginons encore, en suivant cette fois-ci le raisonnement d’un Laurent Alexandre (si, si, j’insiste) : si Safari ne s’était pas appelé Safari l’article du Monde n’aura pas eu ce retentissement, donc la loi Informatique et Libertés n’aurait pas vu le jour, donc la France ne serait pas une colonie numérique des américains, etc. Franchement, on a eu chaud 😉
Totem… et tabou ?
Plus sérieusement, l’épisode Safari a profondément marqué les esprits. On l’a déjà dit, 40 ans plus tard, Safari joue toujours le rôle de totem pour la CNIL. N’est-il pas aussi un tabou ?
L’utilisation du numéro d’inscription au répertoire (votre « numéro de sécurité sociale ») est très encadré, ce qui explique notamment que de nombreux administrations aient défini leurs propres identifiants: numéro délivré par la caisse d’allocation familiale, numéro fiscal, etc. L’interconnexion des bases de données via le NIR est lui aussi très encadré (à vrai dire les progrès de la capacité de traitement des données font qu’on n’a même plus besoin du NIR pour relier deux bases de données… ).
D’autres pays, avec d’autres histoires que la nôtre, ont fait d’autres choix. Ainsi, l’Estonie souvent citée en exemple en matière d’e-administration, délivre une identité numérique obligatoire à tous les Estoniens (95% d’entre eux en sont équipés). Et plusieurs centaines de bases administratives sont interconnectées via cette clé unique. Nous sommes vraiment pas très loin de ce que les concepteurs initiaux de Safari imaginaient !
Dans l’article des Temps Modernes, Missika et Faivret-Lemoine expliquaient, à propos des législations naissantes en Europe en 1977: « apparemment, l’imagination a été mobilisée par le souci de trouver le moyen juridique d’interdire préventivement qu’un nouvel Hitler puisse recourir à l’électronique« .
Et d’adresser cette mise en garde, qui me semble toujours valable 40 ans plus tard: « Le piège serait de préférer forcer la réalité pour y trouver la confirmation de ses craintes plutôt que de faire un bilan plus large et donc plus difficile à interpréter, mais n’excluant pas l’examen de ce qui semble innocent. Croyant affronter le futur, on resterait en fait tragiquement obsédé par le passé et incapable de voir le présent« .
***
Making-off: un grand merci aux documentalistes de la Commission nationale Informatique et Libertés qui ont rassemblé, dans un seul livret, l’ensemble des notes et articles cités dans ce billet de blog:
« Safari ou la chasse aux Français », Philippe Boucher, Le Monde, 21 mars 1974
« Automatisation du répertoire d’identification des personnes physiques. Conception générale », note de l’INSEE, février 1970
« Informatique et libertés », Jean-Louis Missika, Jean-Philippe Faivret, Les temps modernes, septembre-octobre 1977.
Uber et Airbnb ont récemment communiqué sur la mise à disposition volontaire de données issues de leurs services respectifs. Que valent vraiment ces données ? Permettent-elles de répondre aux questions que ces plateformes posent aux territoires ? Ce qui se joue ici c’est bien la capacité à disposer des données pour réguler les grandes plateformes du numérique.
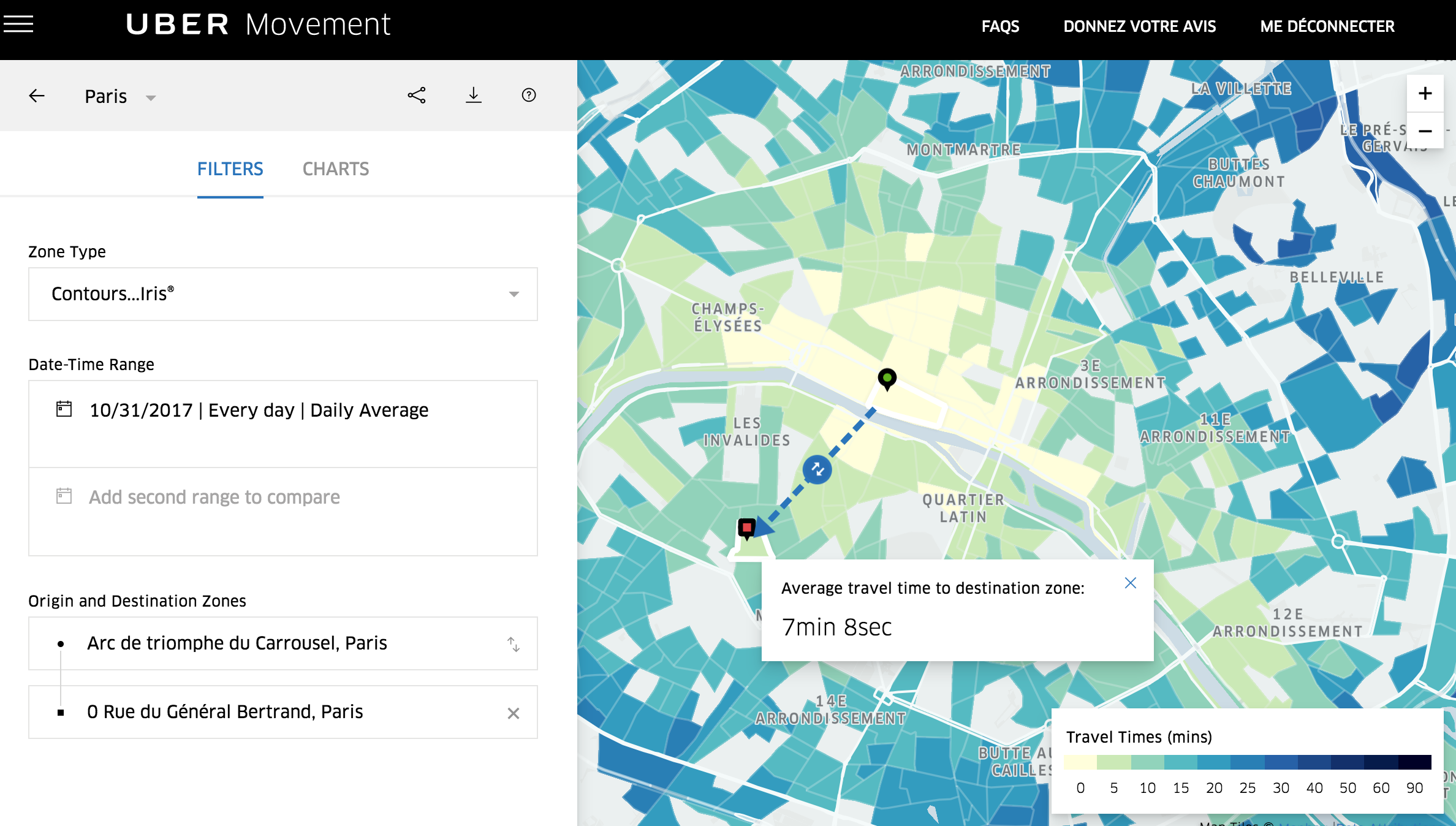
Uber Movement est accessible depuis l’été 2017 pour les villes de Boston, Washington, Manille et Sydney. Les données concernant la région parisienne sont disponibles depuis fin octobre. « Rendre service aux villes et contribuer à répondre à leurs défis de transport et d’aménagements urbains” sont les deux objectifs annoncés officiellement lors du lancement de la plateforme. Concrètement, pour se connecter à Uber Movement il faudra tout d’abord vous inscrire sur la plateforme avec votre email. Les données disponibles concernent les temps de transport entre deux points (aggrégés à des zones IRIS de l’INSEE). Vous pourrez aussi sélectionner, via l’interface des périodes précises (par exemple une seule semaine en 2016 ou 2017, ou le pic de trafic du matin) et télécharger l’ensemble dans un fichier au format CSV. Les données sont disponibles en licence CC-BY-NC, c’est à dire que leur usage commercial n’est pas autorisé.
Dataville by Airbnb
L’annonce du programme Dataville par Airbnb a coincidé avec le salon des Maires de France qui s’est tenu il y a quelques semaines à Paris. A vrai dire il ne s’agit pas d’une coincidence, car dans sa communication officielle Airbnb vise clairement les élus des territoires, expliquant que « le portail permettra aux municipalités de mieux suivre le développement de l’activité touristique via Airbnb sur leur commune, son impact positif sur l’attractivité de leur commune comme sur le pouvoir d’achat de leurs administrés ». L’entreprise insiste d’ailleurs sur son effort de transparence.
Que trouve-t-on sur la plateforme Dataville ?
Le nombre d’annonces dans la ville au 1er septembre 2017
Le nombre de voyageurs accueillis entre septembre 2016 et septembre 2017
Le nombre de pays dont sont originaires les voyageurs qui y ont séjourné
Le revenu annuel médian d’un hôte dans la commune
Toutes ces données sont visualisables via une interface web (comme chez Uber Movement) mais pas du tout téléchargeables (contrairement à Uber).
Open Data où es-tu ?
Commençons très vite par régler ce point: difficile de parler de données ouvertes dans l’exemple d’Airbnb ou d’Uber. Les données d’Uber, bien que téléchargeables, sont diffusées avec une licence qui ne permet pas de les qualifier d’open data car elle interdit expressément tout usage commercial. De même, le fait que l’inscription soit requise pour accéder aux données d’Uber Movement constitue un frein à la réutilisation. C’est pas de l’open data, point.
Des données bien inoffensives
Mais là n’est peut-être pas l’essentiel. Que peut-on dire des données qui sont ainsi volontairement exposées par ces deux entreprises ? Tout d’abord qu’il s’agit bien de données originales, au sens de « qui n’ont pas été exposées auparavant« .
Impossible, avant Uber Movement, de connaître l’historique des temps de transport avec ce niveau de détail. Et Airbnb propose bien, avec Dataville, des données qui n’étaient pas auparavant facilement accessibles, par exemple le nombre de voyageurs ou le nombre de pays d’origine.
Ces données volontairement mises à disposition ont un autre point commun: elles sont inoffensives ! Elles permettent difficilement de répondre aux questions que posent ces plateformes sur les territoires.
Prenons quelques exemples pour nous en convaincre.
Si je suis élu d’une ville où Uber propose son service de VTC, je peux par exemple m’interroger sur son impact sur la congestion urbaine. Est-ce que les clients d’Uber auraient par exemple pu utiliser le réseau de transport en commun, ou est-ce que le VTC permet de pallier une offre défaillante ? Rien dans les données d’Uber Movement ne vous permettra de répondre à cette question. Vous aurez les temps de parcours (ce qui n’est pas inintéressant) mais rien sur le nombre moyen d’utilisateurs du service sur ce même parcours (ce qui serait beaucoup plus utile !), en respectant bien sûr les seuils du secret statistique.
Second exemple, avec Airbnb. Quels sont les termes du débat public concernant Airbnb ? J’en recense au moins trois. Le premier est le risque d’éviction dans les quartiers les plus touristiques, les propriétaires préférant mettre leur logement sur Airbnb que de le louer à l’année (il suffit d’être une fois passé dans le Marais vers 9h-10h quand tout le monde quitte son logement avec des grosses valises pour se rendre compte de quoi l’on parle !).
Second débat, la présence, sur la plateforme, de propriétaires professionnels, bien loin de l’image cool et sympa de celui qui accueille des touristes sur le canapé du salon. Plusieurs articles de presse se sont ainsi fait l’écho de propriétaires qui possèdent plusieurs appartements (voire dizaine d’appartements) sur la plateforme…
Troisième débat, les revenus générés par la plateforme pour les « hôtes » selon la terminologie d’Airbnb. S’agit-il de revenus accessoires ou bien de revenus dignes d’une activité principale (et donc professionnelle) – et qui intéressent donc l’administration fiscale ?
Là encore difficile de répondre à ces questions avec les données mises à disposition par Airbnb. Le niveau de granularité des données est à la commune, pas à l’arrondissement et encore moins au quartier ou à la zone Iris. Pour Paris, on apprend par exemple que 65 000 annonces sont disponibles sur une année, que 2 millions de voyageurs de 178 nationalités différentes ont fréquenté un appartement Airbnb dans la capitale.
C’est grand, Paris. Ce n’est sûrement pas avec ce genre de données qu’on va pouvoir comprendre un peu finement la réalité de l’impact d’Airbnb dans chaque quartier de la capitale !
J’ai fait la même recherche pour la ville de Rennes, et il est précisé que le revenu annuel d’un hôte est de 1400 euros, soit un peu plus de 100 euros par mois. A première vue cela correspond donc bien à des revenus accessoires, du « beurre dans les épinards » (oui, en Bretagne on aime autant le beurre que les épinards…).
Il faut donc aller lire la définition de la métrique selon Airbnb: « valeur médiane du revenu total gagné par l’hôte sur la période d’un an couverte par l’étude. Le revenu annuel est présenté pour un hôte type« . Qu’est-ce qu’un « hôte type » ? L’histoire et Airbnb ne le racontent pas, donc nous sommes en droit d’imaginer. Peut-être qu’un hôte type c’est par exemple un propriétaire qui n’a qu’un appartement et qui ne le met en location que quelques jours par mois ? Autant dire qu’avec de telles métriques nous ne sommes pas prêt de pouvoir répondre à la question de la professionnalisation des « hôtes » Airbnb !
D’ailleurs quand on veut en savoir plus sur le programme on est renvoyés vers le site Airbnb Citizen qui vous propose, au milieu de nombreux témoignages d’utilisateurs de la plateforme, de relayer les campagnes d’influence à destination des élus, comme celle ci-dessous.
C’est plus subtil que du Data-washing
Spontanément nous pourrions crier au data-washing, c’est-à-dire une tentative de se refaire une virginité en publiant des données inoffensives.
Il me semble que les initiatives dont nous parlons ici sont un peu plus subtiles. Ce qui est très clair ce que le choix des données mises à disposition ne doit rien au hasard. Ce n’est pas à un datascientist de chez Uber ou d’Airbnb qu’on va apprendre que des données agrégées sont beaucoup moins utiles que des données détaillées ! Ces sociétés sont réputées pour leur maîtrise des données, on ne peut pas penser une minute qu’elles proposent ces données-là sans avoir envisagé ce qui pourrait (ou plutôt ne pourrait pas) en être fait.
Je pense plutôt que ces initiatives illustrent parfaitement la notion de donnée comme actif stratégique telle que nous la définissions avec Louis-David Benyayer dans Datanomics.
Pour Airbnb ou Uber, la donnée est devenue l’objet et le support de la relation avec les territoires. Lever, ne serait-ce que très légèrement, le voile sur les données c’est aussi se mettre en ordre de bataille pour les discussions à venir, notamment sur les possibles régulations de ces plateformes.
C’est aussi montrer pour mieux cacher, au moment même où les principales métropoles semblent de plus en plus préoccupées par l’impact de ces plateformes sur leur territoire. Si l’on voulait vraiment rentrer dans une régulation par la donnée, telle que proposée par Nick Grossman, alors on ne pourrait pas se contenter des données que les plateformes voudront bien mettre à disposition. La Commission européenne s’intéresse d’ailleurs beaucoup aux données d’intérêt général (1): c’est un outil essentiel pour lutter contre l’asymétrie d’information qui caractérise la relation entre plateformes et territoires !
(1) dans le cadre de la révision en cours de la directive sur les informations du secteur public (PSI).
Data Literacy Conference 2017 (crédit photo Crige Paca)
La seconde édition de la Data Literacy Conference organisée par la Fondation Internet Nouvelle Génération vient de se terminer à Aix-en-Provence. A cette occasion, j’ai eu le plaisir d’animer une table ronde sur la littératie des algorithmes (algo-literacy) avec Sarah Labelle, Dorie Bruyas et Thierry Marcou.
Mieux vivre avec les algorithmes: utiliser, comprendre et créer
Depuis quelques mois, un compte Twitter (@lesalgos) se livre à un détournement des plus intéressants: il re-tweete des articles de presse parlant d’algorithmes en remplaçant ce dernier terme par « les gens ». Le résultat est parfois déroutant, souvent amusant (« failles, biais, erreurs: faut-il croire tout ce que nous disent les gens ?« ). D’objets techniques, les algorithmes sont maintenant devenus des sujets qui semblent animés d’une volonté propre. La littératie des algorithmes – c’est à dire l’aptitude à les comprendre, les utiliser et les critiquer – est l’un des outils dont nous disposons pour dépasser cette vision trop simpliste. Les algorithmes sont là pour durer, que l’on s’en réjouisse ou s’en désole. L’enjeu donc est d’apprendre à mieux vivre avec eux, d’être capables d’en faire à nouveau des objets, d’en décortiquer les rouages pour démont(r)er leur supposée toute-puissance.
Le chemin ne sera pas sans embûches. Celles et ceux qui se frottent à la médiation aux données savent à quel point il faut ruser pour rendre les données plus accessibles et plus compréhensibles au plus grand nombre. Les « visualisations analogiques » de José Duarte, les expériences de Data Cuisine de Susanne Jaschko (tous deux sur scène à Aix-en-Provence cette année) ou les Data-Trucs du programme Infolab sont autant de tentatives souvent réussies de (faire) « mettre les mains dans le cambouis des données ».
Lors de cette table ronde nous sommes allés chercher l’inspiration du côté de la data literacy: est-ce que les grands principes de la médiation aux données (la physicalisation, le jeu, l’apprentissage par la manipulation notamment) s’appliquent aussi aux algorithmes ?
Rendre les algorithmes tangibles et « jouables »
Commençons tout d’abord par mettre les mains dans le « cambouis des algorithmes ». Ce n’est pas évident tant les systèmes numériques ressemblent aux moteurs que l’on découvre aujourd’hui en ouvrant le capot de sa voiture. D’un seul bloc, sans aspérité, le plus souvent même le cambouis semble avoir disparu. Difficile de savoir par où commencer.
Dorie Bruyas est la directrice de Fréquence Ecoles, une association basée à Lyon qui se consacre à l’éducation au numérique et aux médias pour les jeunes et ceux qui les accompagnent. Dorie a présenté l’une des activités qui composent la « valise data » de Fréquence Ecoles. « Youtube Data » est un jeu de cartes qui vous invite à se mettre dans la peau de l’algorithme de recommandation de la plateforme vidéo. Le jeu est composé de 48 cartes représentant un clip vidéo. Au recto on retrouve le nom de la chanson et une photo de l’artiste. Au verso figurent trois éléments sous la forme de métadonnées: les tags (par exemple #pop #miley #usa), un nombre de vues et un historique de consultation. Trois cartes, tirées au sort, sont présentées aux participants (sur leur verso uniquement). A partir des métadonnées les joueurs (à partir de 11 ans) sont invités à deviner ce que l’algorithme de YouTube aurait recommandé: quel sera le quatrième clip proposé ? A la fin de l’activité, l’animateur indique le temps qui aura été nécessaire (de l’ordre de 30 minutes) et indique aux participants que l’algorithme informatisé aurait réalisé cette opération en quelques centaines de millisecondes.
Dans la peau de l’algorithme de recommandation de YouTube (par Fréquence Ecoles)
Bien sûr un tel jeu n’est qu’une représentation très partielle et incomplète du fonctionnement réel de l’algorithme de la plateforme vidéo. Dorie le reconnaît d’ailleurs volontiers. L’enjeu ici est plutôt de provoquer la discussion, la prise de conscience sur des pratiques quotidiennes des jeunes.
Sarah Labelle, maître de conférences à l’Université Paris 13 et partenaire de longue date du programme Infolab, a présenté elle aussi deux expériences qui visent à rendre plus tangibles, plus « manipulables » (au sens littéral) les algorithmes. La première s’appuie elle aussi sur un jeu de cartes, mais il s’agit d’un jeu de cartes classique auquel on retire une carte au hasard. Les « joueurs » (plutôt des adultes) sont invités à prendre le jeu en main et à décrire la recette qu’ils utilisent pour retrouver la carte manquante. Sarah les invite ainsi à « verbaliser » un algorithme (car c’est bien de cela qu’il s’agit). Autre expérience, que nous avons initié tous les trois avec Loic Haÿ lors du forum des usages coopératifs de Brest en 2016 (« ouvrir la boîte noire des algorithmes sans être magicien ni développeur »): trier des chaussettes pour retrouver les paires. Activité quotidienne, triviale même, mais qui permet aussi de montrer que le plus souvent, il y a plusieurs manières de réaliser un objectif selon les contraintes que l’on pose. Par exemple lors de l’un des ateliers, les participants se sont mis à plusieurs pour trier les chaussettes. D’autres ont utilisé l’espace (une très longue table) pour disposer toutes les chaussettes et repérer visuellement les paires. Les plus joueurs ont remis en cause l’objectif même: pour eux, il n’y a rien de choquant à porter des chaussettes dépareillées.
Une invitation à mettre les mains dans le cambouis
La « jouabilité » des algorithmes il en a été question aussi avec Thierry Marcou, co-responsable du programme NosSystèmes de la Fondation Internet Nouvelle Génération. La jouabilité, c’est-à-dire la capacité à interagir librement avec un algorithme est d’ailleurs l’une des pistes explorées par NosSystèmes pour « amorcer une dialogue non-technique avec la technique« . Thierry a cité l’exemple des guides techniques publiés depuis la fin de la seconde guerre mondiale et qui ont connu leur pic de popularité dans les années 80. Chaque guide était consacré à un modèle de véhicule et expliquait, concrètement et pas à pas, comment réaliser les réparations des plus simples (changer un phare) aux plus complexes (remplacer un moteur). Ces guides constituaient de véritables invitations à mettre les mains dans le cambouis ! Dès lors, pourquoi ne pas envisager des guides techniques de l’ère algorithmique, qui permettent à chacun de bricoler un peu les algorithmes du quotidien ?
Défier les algorithmes, provoquer les controverses
CV Dazzle, la mode pour défier les systèmes de reconnaissance facile (NYT)
La littératie des algorithmes peut aussi prendre des chemins de traverse. Ainsi, la controverse est l’un des outils pour mettre en débat les systèmes. L’émergence des systèmes de reconnaissance faciale a provoqué la riposte: des artistes ont imaginé des maquillages / camouflages pour tenter de leur échapper. Ces « peintures de guerre » provoquent le débat sur l’utilisation des technologies, débat d’autant plus nécessaire qu’on apprend que la Chine utilise ces systèmes et le croisement de données personnelles pour « humilier » les piétons qui traversent en dehors des clous…
Parfois ces démarches artistiques ne visent pas tant à créer la controverse qu’à la documenter. Ainsi, les systèmes de police prédictive (dont Predpol) sont déjà sous le feu des critiques pour leur efficacité limitée, les biais des données d’apprentissage ou encore les impacts de l’utilisation de tels systèmes sur l’activité des forces de l’ordre. Le magazine The New Inquiry a récemment mis en ligne une application (aussi disponible sur iOS) de « prédiction de la criminalité en col blanc« . WCCRS (white collar crime risk zones) reprend tous les codes graphiques de Prepol et s’appuie sur les données de l’ensemble des infractions financières commises depuis les années 1960… Bien sûr, derrière la blague potache se dessine la question des priorités de la lutte contre la délinquance.
La prédiction de la criminalité en col blanc (The New Inquiry)
J’étais l’invité hier à Lausanne de la conférence Opendata.ch/2016, le rassemblement annuel de la communauté suisse des données ouvertes. J’ai profité de l’occasion pour prendre un peu de recul sur mes cinq premières années d’open data. Retour sur les principaux éléments de cette présentation.
L’époque des chasseurs-cueilleurs
Kirikoraha ceremony, Sri Lanka, circa 1910 Credit: Wellcome Library, London
Il y a cinq ans, nous étions tous des chasseurs-cueilleurs. Nos « armes » étaient rudimentaires: nos bras, notre arc et quelques flèches. Ou plutôt: des lois sur le droit d’accès à l’information, un momentum politique au niveau international – dont l’icône était Obama version 2008 (c’est-à-dire avant Prism) -, une soif de transparence exprimée par la société civile et des mouvements citoyens plus ou moins organisés.
C’était une belle époque. Mais comme tous les chasseurs-cueilleurs nous avons surtout « attrapé » les animaux les moins rapides et les fruits les plus accessibles selon l’expression consacrée (« low-hanging fruits »). Les jeux de données qui présentaient le plus d’enjeux , en termes de transparence mais aussi de potentiel économique nous restaient largement inaccessibles.
Des échelles pour cueillir les « fruits les moins accessibles »
Alors, comment attraper les fruits les moins accessibles ? L’Homme a inventé l’échelle – et l’homo data sapiens a fait pareil.
Credit: Wellcome Library, London
Nous avons passé ces dernières années à imaginer, construire et poser des échelles. La première d’entre elles, cela a été de construire un rapport de force favorable, en mettant le sujet sur l’agenda politique. La seconde échelle, c’est de faire évoluer la loi – ou plutôt les lois. On a parfois critiqué la difficulté à s’y retrouver dans les nombreux textes qui parlent maintenant d’open data, qu’il s’agisse de la loi sur la gratuité des données (loi Valter), le projet de loi République numérique (loi Lemaire) et les multiples dispositions sectorielles (santé, transports, biodiversité, …). OK. Mais ce sont autant d’échelles qui ont été posées. La troisième échelle ce sont les engagements internationaux; c’est à mon avis le bénéfice le plus concret que l’open data peut tirer de l’adhésion de la France à l’Open Government Partnership. Des engagements ont été pris et il y a déjà des résultats concrets, par exemple sur la commande publique. La quatrième échelle c’est de maintenir la pression citoyenne, qu’elle soit spontanée ou un peu téléguidée comme dans le cas récent de la pétition Citymapper vs. Ratp.
Donc, on a construit des échelles. Et on attrapé des fruits que nous regardions avec envie il y a quelques années encore, que ce soit dans le domaine de la transparence, de la santé, ou de l’économie.
50 nuances de data
A force de cueillir des fruits, on a fini par apprendre une leçon: toutes les données ne se ressemblent pas et ne génèrent pas les mêmes usages. Certaines relèvent du champ de la transparence et du « droit de demander des comptes à tout agent de son administration » (déclaration des droits de l’homme et du citoyen, 1789), par exemple la réserve parlementaire. D’autres ont un potentiel local de services (par exemple des horaires d’ouverture des équipements publics). Et certaines ont une place à part, car elles constituent des références (au sens des données de référence du service public de la donnée).
On a toujours eu un peu de mal à accepter cette idée dans le mouvement open data; de peur sans doute que l’administration soit la seule à décider de ce qui « mérite » d’être ouvert…
Produire, pas uniquement ouvrir
Progressivement les cueilleurs sont devenus des agriculteurs. Et nous avons fait de même: après nous être nous-même nourri de notre cueillette (« eat your own dog food !« ) nous avons commencé à produire nous-même des données. Je pense que la création de la Base adresse nationale représente à ce titre un tournant important, et le fait qu’elle associe des institutions comme La Poste ou l’IGN et les contributeurs d’OpenStreetMap est tout à fait essentiel. La culture de l’open se diffuse par capillarité: d’abord sur la diffusion des données puis maintenant sur leur mode de production lui-même. Les sciences participatives, qui ne datent pas d’hier, ont beaucoup de choses à nous apprendre sur ces pratiques.
L’ouverture est une bataille culturelle
Mais la principale leçon de ces cinq dernières années c’est que l’ouverture est une bataille culturelle. Ouvrir les données, les codes sources mais aussi plus globalement la manière de prendre des décisions et d’agir. Peut-être sommes nous convaincus que l’ouverture, la circulation et la collaboration sont des valeurs partagées par tous – mais c’est une bataille qui vient à peine de commencer. Je repense par exemple à ce sénateur qui répond à l’une de ses collègues que « la loi ne s’écrit pas avec les internautes » alors même que le texte dont ils discutaient avait fait l’objet d’une consultation tout à fait originale en ligne.
Le propre des batailles culturelles c’est qu’elles sont toujours longue à mener … Et il faut bien se l’avouer: nous baignons tellement dans le bouillon numérique que nous avons du mal avec le temps long et sommes naturellement plutôt portés sur les quick wins.
L’Autorité de la concurrence française et son homologue allemande Bundeskartellamt ont publié la semaine dernière une étude sur l’impact des données sur le droit de la concurrence1, et notamment la capacité des acteurs d’un marché à mettre en oeuvre des pratiques anti-concurrentielles (cartels d’entente sur les prix, par exemple). Les données et surtout les algorithmes posent des questions nouvelles, renforcant d’autant plus la nécessité de penser leur régulation.
Quand on parle de cartels et d’ententes illicites, on imagine sans peine la scène suivante: des messieurs dans des costumes de marque, des cigares à la main, se réunissent dans les salons privés et les bars discrets des grands hôtels. Ils échangent des informations sur le marché et se mettent d’accord sur l’évolution des prix et des volumes.
A vrai dire je n’invente pas grand chose dans cette scène: les industriels des produits frais laitiers ont été condamnés en mars 2015 à une amende de 190 millions d’euros pour avoir procédé ainsi pendant plusieurs années. Dans le relevé de la décision de l’Autorité de la concurrence, on peut notamment y lire – cela ne s’invente pas – que les réunions se tenaient à chaque fois dans un hôtel parisien différent et parfois aussi dans la brasserie « Le chien qui fume » située près de Montparnasse …
Les données et les algorithmes vont donner du fil à retordre aux autorités en charge de la concurrence, nous explique en substance l’étude conjointe des deux autorités européennes. Leur préoccupation rejoint celle du département de la Justice américain, dont l’un des représentants a déclaré l’an dernier:
“We will not tolerate anticompetitive conduct, whether it occurs in a smoke-filled room or over the Internet using complex pricing algorithms. American consumers have the right to a free and fair marketplace online, as well as in brick and mortar businesses »2
L’image est destinée à frapper les esprits: les pratiques anti-concurrentielles voient aujourd’hui le jour non plus seulement dans les salons enfumés des hôtels, mais aussi à l’intérieur même du code informatique et des algorithmes. Ces derniers peuvent notamment être programmés pour réagir à des mouvements de prix des concurrents. Ils peuvent même intégrer dans leurs calculs les comportements passés des dits concurrents: comment ont-ils réagi au cours des dernières années ? On retrouve ici la capacité d’apprentissage propre aux traitements de type machine learning.
L’Autorité de la concurrence et le Bundeskartellamt pointent aussi le risque d’une entente non-intentionnelle ou non-coordonnée: les concurrents n’ont plus besoin de se retrouver ou de se mettre d’accord, l’utilisation d’algorithmes de fixation des prix identiques suffit à assurer cette coordination. « Difficult to prove » est l’une des expressions récurrentes de ce document. On voit bien effet qu’il va être très difficile de prouver les intentions d’un cartel qui ne se rencontre jamais, qui n’est jamais en relation, mais qui pourtant aboutit à une réduction de la compétition sur un marché donné !
Il me semble par ailleurs que les données sont un autre élément d’enquête à disposition des autorités de la concurrence. J’ai eu l’occasion il y a deux ans d’accompagner des étudiants de la chaire ESSEC Analytics encadrés par Nicolas Glady. L’un des groupes a ainsi pu travailler sur un cold case: les tarifs des carburants dans les stations-services de France3. Leur travail d’analyse s’est appuyé sur les données historiques proposées en open data par Bercy. On voit bien dans ce cas qu’il y a un intérêt, pour le régulateur, à se doter de capacité à traiter et analyser les données pour trouver de nouveaux indices de comportements anti-concurrentiels (j’utilise à dessein le terme d’indice et non de preuve formelle).
Il faut remettre ces premiers éléments dans une perspective plus large: la régulation des algorithmes et des traitements automatisés. Cette question est le plus souvent abordée sous l’angle de la protection de la vie privée – la Maison Blanche a par exemple pointé récemment le risque de discrimination pour les individus. L’étude de l’Autorité de la concurrence vient à point nommé pour rappeler que l’efficacité de la régulation tient aussi à une meilleure coordination entre le droit de la concurrence et celui qui protège la vie privée des individus (la loi Informatique et Libertés pour notre pays) 4.
— Notes
1 le document est actuellement disponible uniquement en langue anglaise, mais une traduction en français est annoncée.
3 Cold case car la condamnation des principaux pétroliers pour entente illicite sur les tarifs pratiqués dans les stations-services d’autoroute a été annulée par la suite.
4 On peut citer en appui la décision rendue concernant GDF. Saisie par un concurrent (Direct Energies), la société GDF a été condamnée à fournir les données de consommation de ses clients à des tiers pour faciliter l’entrée sur le marché de nouveaux concurrents. En vertu des principes de la loi Informatique et Libertés, les clients de GDF devaient donner leur accord explicite à ce transfert. Et en pratique une très grande part d’entre eux l’ont refusé, réduisant d’autant la portée de la décision de l’autorité de la concurrence.
Internet Actu relate récemment la rencontre organisée par France Stratégies à propos de la responsabilité des algorithmes. Daniel Le Métayer, chercheur à l’INRIA, évoque notamment le fait qu’il est souvent bien difficile de savoir ce que désigne précisement ce terme d’algorithme. « Recette de cuisine » pour les uns, « ensemble de procédés de calcul » pour d’autres et même tout simplement « programme informatique » pour les derniers.
Ce flou n’empêche aucunement le terme algorithme de fleurir un peu partout dans la presse (de moins en moins) spécialisée. Ainsi le débat actuel aux Etats-Unis portent sur l’algorithme de classement de contenu de Facebook, accusé de partialité dans la campagne des primaires (un élu du Dakota du Sud a même demandé à Mark Zuckerberg d’expliciter le fonctionnement de son système de curation).
C’est l’une des caractéristiques des mots-valise: leur imprécision est à la hauteur de leur popularité. Dès lors, on peut légitimement se demander: à qui profite le flou ? Qui a intérêt à continuer à désigner, de manière aussi vague, ces systèmes automatisés de traitement ?
Il faut tout d’abord regarder du côté des concepteurs de ces systèmes. Quand on parle de l’algorithme de Google, ou de celui de Facebook, on tend à résumer ces entreprises à un simple objet technique, a priori asexué et surement neutre. Parler de l’algorithme d’Uber ou de Facebook, se concentrer uniquement sur cela, c’est passer sous silence le modèle économique de ces organisations, le système dans lequel elles interviennent, les valeurs portées par les hommes et les femmes qui les imaginent, les conçoivent, les développent et les optimisent. Il y a de la chair derrière les algorithmes, des passions, des contraintes, des intentions, …
Ensuite le terme d’algorithme fleure bon la précision des mathématiques, des statistiques*. Parler de « programme informatique » c’est beaucoup plus trivial et cela évoque aussi davantage l’idée que le code informatique – et le développeur – sont faillibles. Si l’algorithme est paré des vertus de la science, le code lui est porteur de bugs, de dysfonctionnements, d’imperfections. D’humanité, en quelque sorte.
Enfin, il me semble que le flou entretenu n’est pas un accident. L’utilisation du terme d’algorithme tient à distance. L’objet semble hors de portée, difficile à saisir (comprendre) donc difficile à saisir (tenir). Certains concepteurs évoquent d’ailleurs la complexité des systèmes, et en particulier celles des systèmes apprenants (machine learning) pour s’excuser, par avance, de ne pas être en mesure d’en expliquer le fonctionnement, les intentions et les contraintes. Il me semble pour ma part que l’intelligibilité de ces systèmes est l’une des conditions essentielles de leur acceptabilité sociale et in fine, de la capacité à demander des comptes à ces systèmes (accountability).
* On peut faire le parallèle avec l’origine du mot « donnée » qui évoque l’idée d’un objet exogène (les données du débat), qui vient d’on ne sait où mais n’est pas censé être mis en débat.
Mardi matin, Louis-David Benyayer et moi étions invités par le think tank Renaissance numérique à présenter notre ouvrage Datanomics. Il a notamment été question, lors de cette heure de discussion, de la position de la SNCF et de sa volonté de vendre les données via sa nouvelle API en mode freemium. L’Usine Digitale s’en est fait l’écho, reprenant le tonitruant « Tu déconnes, Yves !« , adressé à Yves Tirode, le patron du digital au sein de la compagnie nationale. Retour sur le sujet, de manière un peu moins… lapidaire.
La SNCF met en oeuvre actuellement son ambitieuse stratégie digitale, qui inclut notamment l’ouverture d’une API d’accès aux données, en mode freemium. La vente de données est présentée comme la solution pour contrer le risque – bien réel ! – que représente Google et les plateformes numériques. Pour ma part, je ne crois pas que la marchandisation des données soit une réponse efficace. Des stratégies alternatives sont déjà mises en oeuvre dans de nombreux secteurs, dont la distribution. Mais avant de les développer, il me semble nécessaire de retracer les enjeux du sujet. La nouvelle stratégie de la SNCF en matière de données s’appuie sur un déjà long historique autour des données ouvertes, que l’on pourrait résumer par la formule de Danah Boyd: « It’s complicated ! ».
1 – Pourquoi c’est compliqué
Le positionnement du groupe SNCF à l’open data est relativement complexe, et reflète bien la diversité des activités de l’entreprise, entre service public (Transilien, TER, Intercités) et activité soumise à la concurrence (TGV et Voyages SNCF).
C’est au sein de sa filiale Keolis que l’on trouve le premier réseau de transports publics urbains à avoir ouvert des données dès 2011 (Keolis Rennes). Le groupe a lancé ses initiatives sur le sujet début 2012, avec l’activité Transilien comme fer de lance (ouverture des données transport de l’Ile de France, bien en amont de la RATP).
Aujourd’hui, le groupe possède un portail Open Data (data.sncf.com) qui propose des données sur l’offre de transport mais aussi des données de transparence (nombre et type d’incidents, conflictualité au sein de l’entreprise, etc…). Depuis lundi dernier, une API, proposée en mode freemium propose une sélection de données, dont certaines temps réel. Cette API propose tous les trains, inclus donc les TGV ce qui représente la vraie nouveauté.
Dernier point, la SNCF s’est engagée dans des relations étroites avec les éco-systèmes numériques (programme « DataShaker SNCF » au Numa, Meet Up Data Transport, …). L’entreprise est aussi impliquée dans des projets collaboratifs, comme la cartographie des gares d’Ile de France sur OpenStreetMap. Enfin, l’open data est aussi pour eux un enjeu de changement de la culture interne, notamment en matière d’innovation ouverte.
Mais ce dynamisme masque difficilement le fait que le sujet open data est longtemps resté très clivant au sein de l’entreprise. Les activités relevant du service public ont une politique offensive sur le sujet, mais l’activité SNCF Voyages – dont est issue le nouveau directeur digital et communication – a adopté, depuis l’origine, une posture beaucoup plus défensive. Ainsi, les données sur l’offre TGV, les horaires temps réel ou encore la tarification ne rentrent dans le périmètre de l’Open Data au sens « données librement et gratuitement réutilisables sans limitation d’usage ».
La SNCF fait valoir que le champ concurrentiel dans lequel l’entreprise opère ne lui permet pas de les ouvrir, au risque de favoriser l’émergence d’acteurs tiers, pas nécessairement les concurrents les plus évidents (ex. Deutsche Bahn) mais plutôt de nouveaux intermédiaires comme Google. Guillaume Pepy est d’ailleurs l’un des patrons français les plus offensifs, et sûrement le plus clairvoyant sur le sujet. Il a, dès 2012, désigné Google comme son principal concurrent.
Le risque de désintermédiation est mis en avant, à l’image de ce qui existe dans l’aérien, où les brokers occupent une place tellement centrale que les compagnies aériennes ont perdu une bonne partie de la relation client, et avec elle la capacité à se démarquer autrement que par les prix.
Ce risque est bien réel. Google propose chaque jour un nombre croissant de services: il pourrait très bien vendre des billets de trains ou encore faire payer à la compagnie ferroviaire une commission pour apport de trafic, comme le fait aujourd’hui Booking dans l’hôtellerie. Franchement, je préfère encore lâcher mes sous pour une entreprise qui paie ses impôts en France (ce qui est aussi le cas de Capitaine Train me semble-t-il) plutôt qu’à l’un des GAFA, qui se caractérisent par l’omniprésence de leur service inversement proportionnelle à leur contribution à l’impôt dans notre pays.
2 – La donnée TGV est un actif stratégique avant d’être une matière première
L’idée de l’API freemium est de faire payer les données selon le niveau d’usage. Cela permettrait a priori de réconcilier deux objectifs: favoriser l’innovation ouverte (en ouvrant les données, y compris temps réel, aux petites start-ups) et se prémunir de l’hégémonie des grands acteurs du web (qui paieraient plein pot). Et c’est là, à mon avis, qu’il y a un besoin de clarification.
Dans Datanomics, nous avons identifiés trois facettes de la valeur des données:
– quand elles sont revendues par ceux qui les collectent, les produisent ou les aggrègent, les données prennent une forme de matière première,
– quand elles sont utilisées, sans marchandisation, par exemple pour réduire les coûts ou développer les revenus, elles prennent une forme de levier,
– enfin, quand elles constituent une arme stratégique pour défendre et conquérir une position concurrentielle, elles prennent une valeur d’actif.
Ces trois facettes de la valeur ne sont pas exclusives. Certaines entreprises ou certaines données, révèlent plusieurs formes simultanées de valeur. Cette grille me semble pertinente pour voir ce qui se joue autour de la vente des données TGV. Il faut considérer la donnée comme un actif stratégique qui permet de défendre un marché ou de conquérir une nouvelle position, et pas uniquement comme une matière première que l’on vend et que l’on achète.
On ne connait pas encore la grille tarifaire de l’API SNCF. Elle doit être annoncée cet été. Mais on peut au moins regarder ce qui se fait à l’étranger. Au Royaume-Uni, une start-up accompagnée par l’Open Data Institute propose un service similaire, Transport API. Sa grille tarifaire est en ligne. On peut ainsi y lire que pour un accès illimité, sans contrainte de nombre de requêtes, il faut s’acquitter d’un peu plus de 100 000 euros par an.
Admettons que la SNCF arrive à placer la barre encore plus haut et qu’elle fixe les tarifs, pour un acteur gros consommateur de son API freemium (genre Google) à 1 million d’euros par an. A partir de là, on a deux hypothèses. La première: Google accepte de payer. 1 million d’euros: ca fait déjà une très jolie somme, sur le marché de la donnée. Mais rappelons juste qu’une rame de TGV cela coûte entre 15 et 20 millions d’euros. On ne brade pas un actif stratégique pour le prix d’un demi-wagon de train. La seconde hypothèse: Google ne veut pas payer. C’est un peu une stratégie « à la Grand Lyon« : je fixe un tarif qui, en résumé, veut dire: « on ne veut pas de vous ».
Dans cette optique, la SNCF ne veut en réalité pas vendre ses données à Google.
Considérer la donnée comme un actif stratégique, c’est notamment l’utiliser pour construire un rapport de force favorable. Ce qui fait la vraie richesse de Twitter ou Facebook ce n’est pas de vendre les données aux développeurs, mais de maîtriser le robinet, en l’occurrence l’API. Le pouvoir de ces entreprises c’est de décider des conditions d’accès, et de pouvoir les modifier sans préavis. Ce qui est vrai pour Twitter l’est aussi pour le gouvernement américain: le GPS est accessible gratuitement, mais les américains se réservent le droit de dégrader ou d’interrompre le service.
Le GPS est d’ailleurs un bon exemple où la donnée a un coût important (on évalue le programme à 14 milliards de dollars), une valeur d’usage très forte (70 milliards de dollars par an) mais un prix égale à zéro. L’argument « cela doit avoir un prix parce que cela a un coût » n’est pas toujours vrai. Dans le domaine de la distribution aussi, la donnée permet de recomposer la chaîne de valeur. Walmart offre ainsi à tous ses fournisseurs une donnée temps réel sur les niveaux de stocks et de vente de leurs produits (Walmart Retail Link). En procédant ainsi, le géant américain renverse la responsabilité: c’est au fabriquant de s’assurer que le produit est disponible. Cette donnée n’est pas vendue, mais cela ne l’empêche d’avoir une valeur stratégique très forte.
Ce débat ne concerne pas que la SNCF. Toutes les entreprises qui produisent des données se posent les mêmes questions et sont confrontées aux mêmes enjeux. Mais ce serait une erreur de les laisser croire que la marchandisation est une réponse au risque que représente les plateformes du numérique…
Le point de départ, une interrogation et une insatisfaction
Lorsque nous avons commencé à travailler sur la question de la valeur des données, nous constations chaque jour un décalage croissant entre les pratiques des données et notre compréhension, souvent partielle, de leurs enjeux techniques, économiques, politiques et sociétaux. Face à cette réalité, les discours, les raisonnements et les débats sont fragmentés. Même notre « pensée » sur les données est en silos. On continue de structurer les échanges par type de données : personnelles, ouvertes, massives. Cette approche, qui conduit à des discours d’expertise, ne nous aide pas à comprendre les interactions entre toutes ces dimensions.
Pour sortir du flou, il fallait choisir une clé de lecture. La question de la valeur et les discours qui lui sont associés nous ont semblé pertinents pour éclairer les changements en cours. La valeur, forcément subjective, que nous accordons aux données est à la fois la cause et la conséquence de nos actions, le déterminant et le résultat.
Une double question nous animait au moment de commencer cette exploration de la valeur des données : où est la valeur, se mesure-t-elle uniquement en euros, ça change quoi pour les individus, les entreprises et la société ?
Une année d’exploration
Pour nourrir cette question, nous avons régulièrement interagi en ligne et lors d’événements pour établir les thèmes les plus saillants et mettre à l’épreuve nos principales hypothèses.
Nous remercions en particulier celles et ceux qui ont contribué par leurs réactions et leurs travaux à cette exploration : Henri Verdier, Valérie Peugeot, Daniel Kaplan, Bruno Marzloff, Bernard Stiegler, Yann Moulier-Boutang, Nicolas Colin, Christophe Benavent, Hubert Guillaud, Lionel Maurel, Camille Domange, Stéphane Schultz et Adnène Trojette, Romain Lalanne, Frédéric Charles, Christian Quest, Loïc Hay, Stéphane Derville, Stéphan Minard, Charles Népote, Chloé Bonnet, Kat Borlongan, Guillaume Crouigneau, Tristan Nitot, l’équipe de la mission Etalab et Olivier Mamavi.
Un livre pour alimenter le débat
Après ce travail d’exploration, les événements et débats récents confirment que le travail de pédagogie reste entier. Plusieurs organisations ou individus s’engagent pour l’alimenter (par exemple OpenClassrooms ou Tristan Nitot) et nous avons écrit ce livre pour participer à ce débat.
Cet essai explore les transformations engendrées par un monde de données abondantes.
La première transformation concerne la façon dont nous produisons et collectons aujourd’hui des données. Ce phénomène, appelé « big data », n’est pas qu’une affaire de volume : il change fondamentalement la nature même des données qui peuvent être mobilisées.
La deuxième est liée aux fondements de la valeur : la rareté a cédé la place à l’abondance. Les données ne valent pas tant pour ce qu’elles sont, mais plutôt pour ce qu’elles permettent de faire et pour les positions stratégiques auxquelles elles donnent accès.
La troisième transformation est liée à l’émergence d’une économie de la donnée selon trois facettes : la matière première, le levier et l’actif stratégique. Bien plus qu’un bien qui se vend et s’achète, la donnée est un outil puissant pour décider, agir et produire autrement, mais aussi pour prendre place au sein d’un écosystème.
Le propos ne serait pas complet sans une analyse critique des impacts pour les entreprises, l’acteur public et les individus. Car les données sont pour chacun une source d’opportunités et de menaces. Elles rebattent les cartes de la concurrence, interrogent les services publics dans leurs missions et interpellent les individus sur leur capacité à ne pas être « prisonniers des algorithmes », mais plutôt à utiliser les données comme un levier d’émancipation.
Datanomics s’adresse à ceux qui veulent comprendre et agir. Pour participer au débat nous vous invitons à utiliser #datanomics sur twitter et à parcourir le scoopit Datanomics.